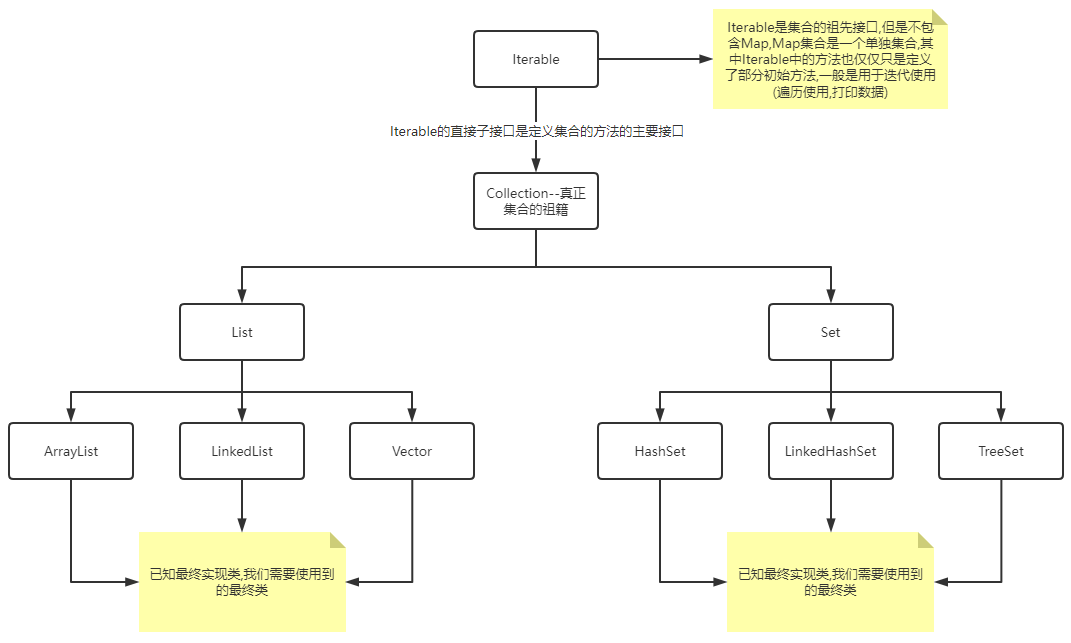
Java集合体系




数组存在问题:
数组长度固定
存入的类型只能是一种(数据单一)
数组是线性结构,增删效率低
假设现在有一个情景需求,统计一个学校的学生,如果使用数组则需要固定长度,而一旦固定了之后,加入学校开除学生了则不能减少数组长度,同样如果学校中途又来了学生也没办法添加;所以数组是无法解决这个问题的,因为学生的统计是不固定的,有可能会增加也有可能会减少;所以出现了集合
集合的出现就是为了解决数组的问题,所以能够确定一点就是集合更加的强大;集合存储数据必须是引用数据类型
集合体系
Collection接口体系
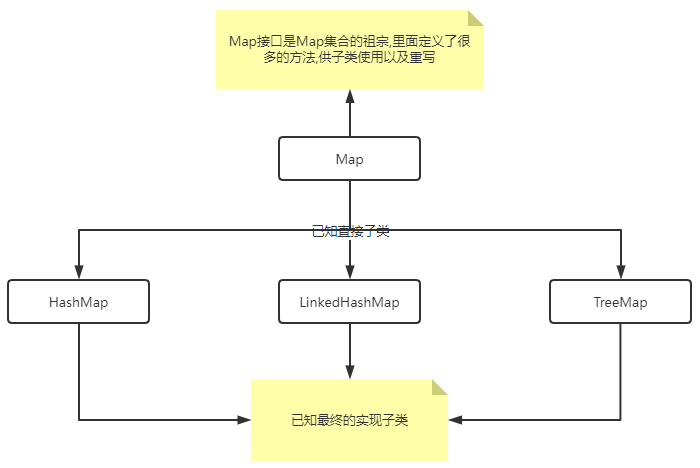
Map接口体系
Collection接口
boolean add(E e):向集合中添加元素boolean addAll(Collection<? extends E> c):向集合中添加一个集合元素boolean contains(Object o):检测集合中是否包含某个元素boolean containsAll(Collection<?> c):检测集合中是否包含另一个集合中的元素boolean remove(Object o):从集合中移除指定数据(对象)boolean removeAll(Collection<?> c):移除此集合的所有也包含在指定集合中的元素
int size():返回集合中的元素数量boolean isEmpty():判断集合是否为空Object[] toArray():将集合转为数组void clear():清空集合内元素Iterator<E> iterator():返回集合迭代器元素,用于遍历集合中的所有元素代码案例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52public class CollectionDemo {
public static void main(String[] args) {
// 由于Collection是接口所以无法直接创建对象,所以使用其子类创建(ArrayList)
// 以多态方式创建Collection接口集合,并且只能使用Collection接口中的方法
Collection collection = new ArrayList();
// 1. `boolean add(E e)`:向集合中添加元素
collection.add("彭于晏");
collection.add(18);
collection.add(185.2);
collection.add("男");
System.out.println(collection);
// 2. `boolean addAll(Collection<? extends E> c)`:向集合中添加一个集合元素
Collection collection1 = new ArrayList();
collection.add("吴彦祖");
collection.add(19);
collection.add(182.2);
collection.add("男");
collection.addAll(collection1);
System.out.println(collection);
// 3. `boolean contains(Object o)`:检测集合中是否包含某个元素
boolean isContains = collection.contains("吴彦祖");
System.out.println(isContains);
isContains = collection.contains("吴彦祖1");
System.out.println(isContains);
// 4. `boolean containsAll(Collection<?> c)`:检测集合中是否包含另一个集合中的元素
boolean isContainsAll = collection.containsAll(collection1);
System.out.println(isContainsAll);
// collection1中再添加一条数据
collection1.add("帅");
isContainsAll = collection.containsAll(collection1);
System.out.println(isContainsAll);
// 5. `boolean remove(Object o)`:从集合中移除指定数据(对象)
boolean isRemove = collection.remove("帅");
System.out.println(isRemove);
System.out.println(collection);
isRemove = collection.remove("男");
System.out.println(isRemove);
System.out.println(collection);
// 6. `boolean removeAll(Collection<?> c)`:移除此集合的所有也包含在指定集合中的元素
// 7. `boolean retainAll(Collection<?> c)`:移除刺激和的所有不包含在指定集合中的元素(移除非相同的元素,非交集元素)
// 8. `int size()`:返回集合中的元素数量
System.out.println(collection.size());
// 9. `boolean isEmpty()`:判断集合是否为空
System.out.println(collection.isEmpty());
// 10. `Object[] toArray()`:将集合转为数组
// 11. `void clear()`:清空集合内元素
collection.clear();
System.out.println(collection);
System.out.println(collection.isEmpty());
// 12. `Iterator<E> iterator()`:返回集合迭代器元素,用于遍历集合中的所有元素
}
}List接口
boolean add(E e):向List集合中添加元素常用void add(int index, E element):向List集合中指定位置添加元素boolean addAll(Collection<? extends E> c):将指定集合中的所有元素追加到此集合的末尾boolean addAll(int index, Collection<? extends E> c):将指定集合中的所有元素追加到此集合的指定位置boolean contains(Object o):检测此集合中是否包含指定元素常用boolean containsAll(Collection<?> c):检测集合中是否包含另一个集合中的元素E get(int index):获取集合中指定下标索引的元素并返回常用E set(int index, E element):修改集合中指定下标索引的元素int indexOf(Object o):在集合中查找元素如果存在则返回此元素的下标索引(返回第一次发现的下标索引)int lastIndexOf(Object o):在集合中查找元素如果存在则返回此元素的下标索引(返回最后一次发现的下标索引)List<E> subList(int fromIndex, int toIndex):切割集合,指定起始位置和结束位置ListIterator<E> listIterator():返回List接口迭代器int size():返回集合中的元素数量常用boolean isEmpty():判断集合是否为空常用Object[] toArray():将集合转为数组void clear():清空集合内元素Iterator<E> iterator():返回集合迭代器元素,用于遍历集合中的所有元素
代码案例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155public class ListDemo {
public static void main(String[] args) {
// 使用多态方式创建List接口对象-->使用其子类ArrayList
List list = new ArrayList();
// 1. `boolean add(E e)`:向List集合中添加元素`常用`
list.add("彭于晏");
list.add(18);
list.add("男神");
System.out.println(list);
// 2. `void add(int index, E element)`:向List集合中指定位置添加元素
list.add(2, 185.3);
System.out.println(list);
// 3. `boolean addAll(Collection<? extends E> c)`:将指定集合中的所有元素追加到此集合的末尾
// 4. `boolean addAll(int index, Collection<? extends E> c)`:将指定集合中的所有元素追加到此集合的指定位置
// 5. `boolean contains(Object o)`:检测此集合中是否包含指定元素`常用`
boolean isContains = list.contains("彭于晏");
System.out.println(isContains);
isContains = list.contains("彭于晏1");
System.out.println(isContains);
// 6. `boolean containsAll(Collection<?> c)`:检测集合中是否包含另一个集合中的元素
// 7. `E get(int index)`:获取集合中指定下标索引的元素并返回`常用`
Object o = list.get(0);
System.out.println(o);
// 如果调用超出范围则报异常-->IndexOutOfBoundsException: Index: 100, Size: 4
// Object o1 = list.get(100);
// System.out.println(o1);
// 8. `E set(int index, E element)`:修改集合中指定下标索引的元素
// 返回的结果是修改前的内容
Object set = list.set(2, 185.0);
System.out.println(set);
System.out.println(list);
// 9. `int indexOf(Object o)`:在集合中查找元素如果存在则返回此元素的下标索引(返回第一次发现的下标索引)
// 在集合中多添加一些数据
list.add("男");
list.add("男神");
System.out.println(list);
int index = list.indexOf("男神");
System.out.println("返回下标:" + index);
// 如果不存在则返回-1
index = list.indexOf("男神123");
System.out.println("返回下标:" + index);
// 10. `int lastIndexOf(Object o)`:在集合中查找元素如果存在则返回此元素的下标索引(返回最后一次发现的下标索引)
index = list.lastIndexOf("男神");
System.out.println("返回下标:" + index);
// 如果不存在则返回-1
index = list.lastIndexOf("男神123");
System.out.println("返回下标:" + index);
// 11. `List<E> subList(int fromIndex, int toIndex)`:切割集合,指定起始位置和结束位置
List subList = list.subList(0, 2);
System.out.println(subList);
// 12. `ListIterator<E> listIterator()`:返回List接口迭代器
// 13. `int size()`:返回集合中的元素数量`常用`
// 14. `boolean isEmpty()`:判断集合是否为空`常用`
// 15. `Object[] toArray()`:将集合转为数组
// 16. `void clear()`:清空集合内元素
// 17. `Iterator<E> iterator()`:返回集合迭代器元素,用于遍历集合中的所有元素
System.out.println("========================================");
// 使用迭代器
// `Iterator<E> iterator()`:返回集合迭代器元素,用于遍历集合中的所有元素
Iterator iterator = list.iterator();
// 迭代器方法boolean hasNext();-->判断iterator中是否还有可迭代的元素
// 迭代器方法E next();-->输出迭代器中的元素-->类似于指针每次调用都会向后移
// next如果超出范围则报错-->NoSuchElementException
// 将next指针指向下一个元素
/*Object next = iterator.next();
System.out.println(next);
// 将next指针指向下一个元素
next = iterator.next();
System.out.println(next);
// 将next指针指向下一个元素
next = iterator.next();
System.out.println(next);
// 将next指针指向下一个元素
next = iterator.next();
System.out.println(next);
// 将next指针指向下一个元素
next = iterator.next();
System.out.println(next);
// 将next指针指向下一个元素
next = iterator.next();
System.out.println(next);
// 将next指针指向下一个元素
next = iterator.next();
System.out.println(next);
// 将next指针指向下一个元素
next = iterator.next();
System.out.println(next);
// 将next指针指向下一个元素
next = iterator.next();
System.out.println(next);
// 将next指针指向下一个元素
next = iterator.next();
System.out.println(next);
// 将next指针指向下一个元素
next = iterator.next();
System.out.println(next);*/
// iterator.hasNext()验证是否有下一条数据
/*boolean b = iterator.hasNext();
System.out.println(b);
iterator.next();
b = iterator.hasNext();
System.out.println(b);
iterator.next();
b = iterator.hasNext();
System.out.println(b);
iterator.next();
b = iterator.hasNext();
System.out.println(b);
iterator.next();
b = iterator.hasNext();
System.out.println(b);
iterator.next();
b = iterator.hasNext();
System.out.println(b);
iterator.next();
b = iterator.hasNext();
System.out.println(b);
iterator.next();
b = iterator.hasNext();
System.out.println(b);
iterator.next();
b = iterator.hasNext();
System.out.println(b);
iterator.next();
b = iterator.hasNext();
System.out.println(b);
iterator.next();
b = iterator.hasNext();
System.out.println(b);*/
// 使用while循环
// iterator.hasNext()判断是否存在元素
// list.clear();
// iterator = list.iterator();
while (iterator.hasNext()) {
// 将next指针指向下一条数据
Object next = iterator.next();
// 输出结果
System.out.println(next);
}
System.out.println("========================================");
// for循环遍历与上面的iterator迭代器相同都是遍历
for (Object o1 : list) {
System.out.println(o1);
}
System.out.println("========================================");
// `ListIterator<E> listIterator()`:返回List接口迭代器
ListIterator listIterator = list.listIterator();
while (listIterator.hasNext()) {
Object next = listIterator.next();
System.out.println(next);
}
}
}List接口之实现类ArrayList
ArrayList概述
ArrayList–>仅从名字看是数组集合–>ArrayList其底层是数组实现的,但是通过某些手段实现了可变长度的数组(动态数组),其容量可以自动增长动态增加容量
官方解释:List接口的可调整大小的数组实现(ArrayList是List接口的实现类,并且是动态数组大小)。实现了List接口的所有操作,并允许添加所有元素,包括null(但不建议添加null) 。除了实现List接口之外,该类还提供了一些自己的方法用来实现动态数组大小的方法;
(注意:ArrayList类与Vector类的方法相同,不同之处在于ArrayList是线程不安全,而Vector是线程安全)ArrayList中的底层实现源码
1
2
3
4
5
6public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
// ArrayList底层实现是使用数组实现的
// transient-->(瞬时/瞬态/短暂的)-->如果通过网络传输此对象或向文件中写入此对象则不保留的字段(此字段不传输的内容)
// 通过transient关键字修饰的只能在Java中使用,不能传输(例如写入文件和网络传输)
transient Object[] elementData;
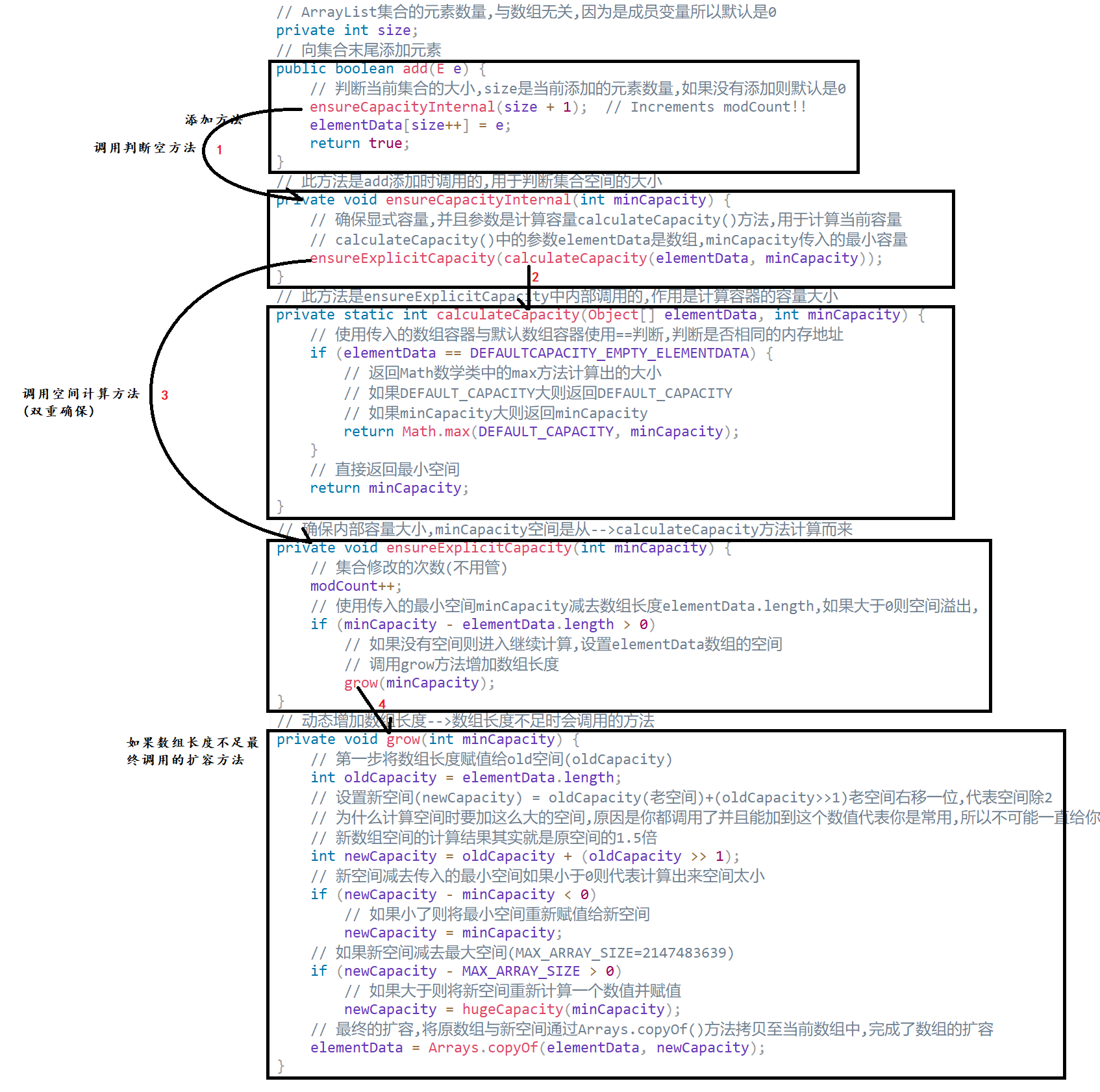
}ArrayList添加方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56// ArrayList集合的元素数量,与数组无关,因为是成员变量所以默认是0
private int size;
// 向集合末尾添加元素
public boolean add(E e) {
// 判断当前集合的大小,size是当前添加的元素数量,如果没有添加则默认是0
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
// 此方法是add添加时调用的,用于判断集合空间的大小
private void ensureCapacityInternal(int minCapacity) {
// 确保显式容量,并且参数是计算容量calculateCapacity()方法,用于计算当前容量
// calculateCapacity()中的参数elementData是数组,minCapacity传入的最小容量
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
// 此方法是ensureExplicitCapacity中内部调用的,作用是计算容器的容量大小
private static int calculateCapacity(Object[] elementData, int minCapacity) {
// 使用传入的数组容器与默认数组容器使用==判断,判断是否相同的内存地址
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 返回Math数学类中的max方法计算出的大小
// 如果DEFAULT_CAPACITY大则返回DEFAULT_CAPACITY
// 如果minCapacity大则返回minCapacity
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
// 直接返回最小空间
return minCapacity;
}
// 确保内部容量大小,minCapacity空间是从-->calculateCapacity方法计算而来
private void ensureExplicitCapacity(int minCapacity) {
// 集合修改的次数(不用管)
modCount++;
// 使用传入的最小空间minCapacity减去数组长度elementData.length,如果大于0则空间溢出,
if (minCapacity - elementData.length > 0)
// 如果没有空间则进入继续计算,设置elementData数组的空间
// 调用grow方法增加数组长度
grow(minCapacity);
}
// 动态增加数组长度-->数组长度不足时会调用的方法
private void grow(int minCapacity) {
// 第一步将数组长度赋值给old空间(oldCapacity)
int oldCapacity = elementData.length;
// 设置新空间(newCapacity) = oldCapacity(老空间)+(oldCapacity>>1)老空间右移一位,代表空间除2
// 为什么计算空间时要加这么大的空间,原因是你都调用了并且能加到这个数值代表你是常用,所以不可能一直给你默认一个数值
// 新数组空间的计算结果其实就是原空间的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 新空间减去传入的最小空间如果小于0则代表计算出来空间太小
if (newCapacity - minCapacity < 0)
// 如果小了则将最小空间重新赋值给新空间
newCapacity = minCapacity;
// 如果新空间减去最大空间(MAX_ARRAY_SIZE=2147483639)
if (newCapacity - MAX_ARRAY_SIZE > 0)
// 如果大于则将新空间重新计算一个数值并赋值
newCapacity = hugeCapacity(minCapacity);
// 最终的扩容,将原数组与新空间通过Arrays.copyOf()方法拷贝至当前数组中,完成了数组的扩容
elementData = Arrays.copyOf(elementData, newCapacity);
}
ArrayList获取方法
1
2
3
4
5
6
7
8
9
10
11
12// 获取下标索引元素方法
public E get(int index) {
// 验证输入的index是否超出范围,超出则抛异常
rangeCheck(index);
// 返回index小表索引的元素
return elementData(index);
}
// 获取index下标索引元素的方法
E elementData(int index) {
// 返回数组当前index下标元素;例如:String[]strs = {"a","b","c"}-->strs[1]
return (E) elementData[index];
}ArrayList修改方法
1
2
3
4
5
6
7
8
9
10
11// 修改方法
public E set(int index, E element) {
// 验证输入的index是否超出范围,超出则抛异常
rangeCheck(index);
// 获取当前数组index下标索引的元素
E oldValue = elementData(index);
// 将当前index下标索引数据修改为传入的数据
elementData[index] = element;
// 返回修改前的内容
return oldValue;
}ArrayList使用代码案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public class ArrayListDemo {
public static void main(String[] args) {
// 使用ArrayList集合,注意通常使用ArrayList都是使用多态方式创建既:List list=new ArrayList()这种方式
ArrayList arrayList = new ArrayList();// 默认
// 追加数据-->会扩容到10大小的空间
arrayList.add("小明");
System.out.println(arrayList);
// 插入数据
arrayList.add(0, "彭于晏");
System.out.println(arrayList);
// 修改数据
arrayList.set(1, "吴彦祖");
System.out.println(arrayList);
// 移除数据
arrayList.remove("吴彦祖");
System.out.println(arrayList);
// 获取数据
Object o = arrayList.get(0);
System.out.println(o);
}
}重写实现ArrayList部分功能
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147/**
* 自定义实现ArrayList部分方法
*/
public class ArrayList {
// 使用数组当做集合的底层存放
private Object[] elementData;
// 用于记录集合中元素数量的变量
private int size;
/**
* 默认初始化数组空间即可
*/
public ArrayList() {
// 创建数组并分配默认空间-->默认10即可
this.elementData = new Object[10];
}
/**
* 创建自定义容量大小的构造方法
*
* @param initCapacity 初始化容量
*/
public ArrayList(int initCapacity) {
// 创建数组并分配默认空间-->默认10即可
this.elementData = new Object[initCapacity];
}
/**
* 添加元素方法
*
* @param element 传入需要添加的元素
* @return 返回是否添加成功
*/
public boolean add(Object element) {
// 判断容量是否需要扩容
ensureCapacityInternal();
// 将数据添加至数组中-->其中size代表当前集合中的数据有多少
this.elementData[size++] = element;
return true;
}
private void ensureCapacityInternal() {
// 使用size与数组长度对比,如果size大了则代表需要扩容
/*if (size >= this.elementData.length) {
// 将数组长度获取并赋值
int oldLength = this.elementData.length;
// 创建新数组并指定空间大小
Object[] newElementData = new Object[oldLength + (oldLength >> 1) + 1];
// 使用循环遍历方式将数据转义至新数组中-->带着大家使用原始方式来一遍
// 根据老数组的长度计算循环
for (int i = 0; i < this.elementData.length; i++) {
// 循环将原始数组数据复制给新数组
newElementData[i] = this.elementData[i];
}
// 重新赋值后再将this.elementData重新赋值指向新数组内存地址
this.elementData = newElementData;
}*/
// 模仿官方写法
if (size >= this.elementData.length) {
// 将数组长度获取并赋值
int oldCapacity = this.elementData.length;
// 计算新空间大小
int newCapacity = oldCapacity + (oldCapacity >> 1) + 1;
// 使用数组工具类拷贝数组
this.elementData = Arrays.copyOf(this.elementData, newCapacity);
}
}
/**
* 获取集合中的元素
*
* @param index 传入下标索引
* @return 返回当前下标元素
*/
public Object get(int index) {
// 验证传入的index是否超出索引范围
rangeCheck(index);
// 返回数据
return this.elementData[index];
}
/**
* 检查传入的index是否超出范围
*
* @param index 传入的下标索引
*/
private void rangeCheck(int index) {
// 判断index是否小于0,以及是否大于size
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException("数组下标索引超出范围:" + index);
}
}
/**
* 修改元素
*
* @param index 传入需要修改的下标索引
* @param element 传入修改的数据
* @return 返回修改前的数据
*/
public Object set(int index, Object element) {
// 验证下标是否合法
rangeCheck(index);
// 将老数据提取
Object oldElementData = this.elementData[index];
// 修改index下标索引的数据
this.elementData[index] = element;
return oldElementData;
}
/**
* toString方法用于打印数据
*
* @return 返回的是数组中的元素数据
*/
@Override
public String toString() {
return "ArrayList{" +
"elementData=" + Arrays.toString(elementData) +
'}';
}
}
// 测试方法
public class MyArrayListDemo {
public static void main(String[] args) {
// 创建自己写的ArrayList
ArrayList list = new ArrayList();
// 添加数据
for (int i = 0; i < 50; i++) {
list.add("添加数据测试" + i);
}
// 打印结果
System.out.println(list);
// 获取数据
System.out.println(list.get(1));
System.out.println(list.get(3));
System.out.println(list.get(5));
System.out.println(list.get(7));
// System.out.println(list.get(-1));
System.out.println("============================================");
// 修改数据
Object oldElementData = list.set(1, "彭于晏");
System.out.println(oldElementData);
System.out.println(list);
}
}ArrayList集合中使用泛型约束添加数据的类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43public class ListGenericsDemo {
public static void main(String[] args) {
// 集合中的泛型
// 在未使用泛型时向集合添加数据,由于数据的不统一,造成无法准确调用集合中元素的私有方法
List list = new ArrayList();
// 添加数据
list.add(new Person("彭于晏1", "男", 18));
list.add(new Person("彭于晏2", "男", 19));
list.add(new Person("彭于晏3", "男", 20));
// 添加其他数据
list.add("String类型数据");
list.add("String类型数据");
list.add("String类型数据");
// 取出数据
Person person = (Person) list.get(2);
System.out.println(person.getName());
// 获取下标为3的数据,下标为3的是String类型,转换对象时不属于同一个类型,会出现类型转换异常
// Person person1 = (Person) list.get(3);
// System.out.println(person1.getName());
// 不转
// Object o = list.get(0);
// 只能调用Object类的方法
System.out.println("===============================================");
// 所以集合中有一个泛型的概念,泛型的作用就是用于约束类中的参数(参数可以代表:属性,形参,实参)传输-->泛型用于约束/规则
// 使用泛型的集合
// 格式例如:List<泛型类型(任意类型)> list = new ArrayList<>();
// 定义一个List集合,泛型类型为Person,代表着只能向集合中添加Person对象数据
List<Person> persons = new ArrayList<>();
// 添加数据,如果添加的数据不是泛型类型则会出现编译异常
// Required type:Person-->需要类型是Person
// Provided:String-->但是提供的是String类型
// persons.add("String类型数据");
// 添加准确数据
persons.add(new Person("彭于晏1", "男", 18));
persons.add(new Person("彭于晏2", "男", 19));
persons.add(new Person("彭于晏3", "男", 20));
// 获取数据
Person person2 = persons.get(0);
System.out.println(person2);
System.out.println(person2.getName() + "-" + person2.getSex());
}
}**注意:**集合中使用泛型的目的是为了约束添加数据时的类型–>统一数据类型,统一数据类型的目的使用使用时不用强转,同样也不会因为强转而发生类型转换异常–>后期所有的集合都需要指定泛型类型
List接口之实现类LinkedList
LinkedList概述
LinkedList底层是使用链表存储数据,使用链表存储数据是为了解决ArrayList使用数据存储数据的问题–>数据存储查询速度快,但是插入删除速度慢,LinkedList链表结构是查询速度慢,插入删除速度快–>LinkedList底层的存储方式就是使用双链表结构存储,在其中有一个内部类Node–>节点,存储数据
LinkedList中的链表是什么?
链表存储时数据不连续(属于数据之间是非连续空间),空间不连续也就意味着无法通过下标指向某一个元素,所以就出现了一个问题,只要查找数据就必须遍历所有的集合数据进行查找
链表分为4种类型
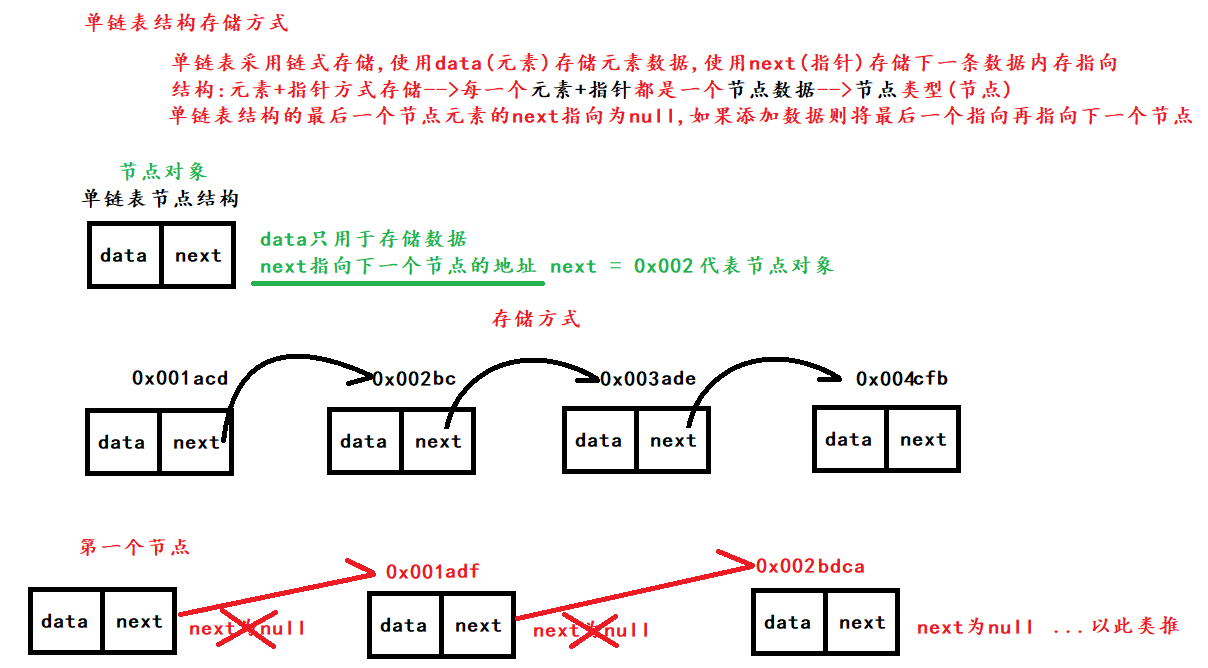
单链表
单链表结构:单链表存储使用节点方式(节点就是一个对象),
存储数据时有两个属性:
data:存放数据
next:指针,指向下一个节点地址,最后一个节点存储null
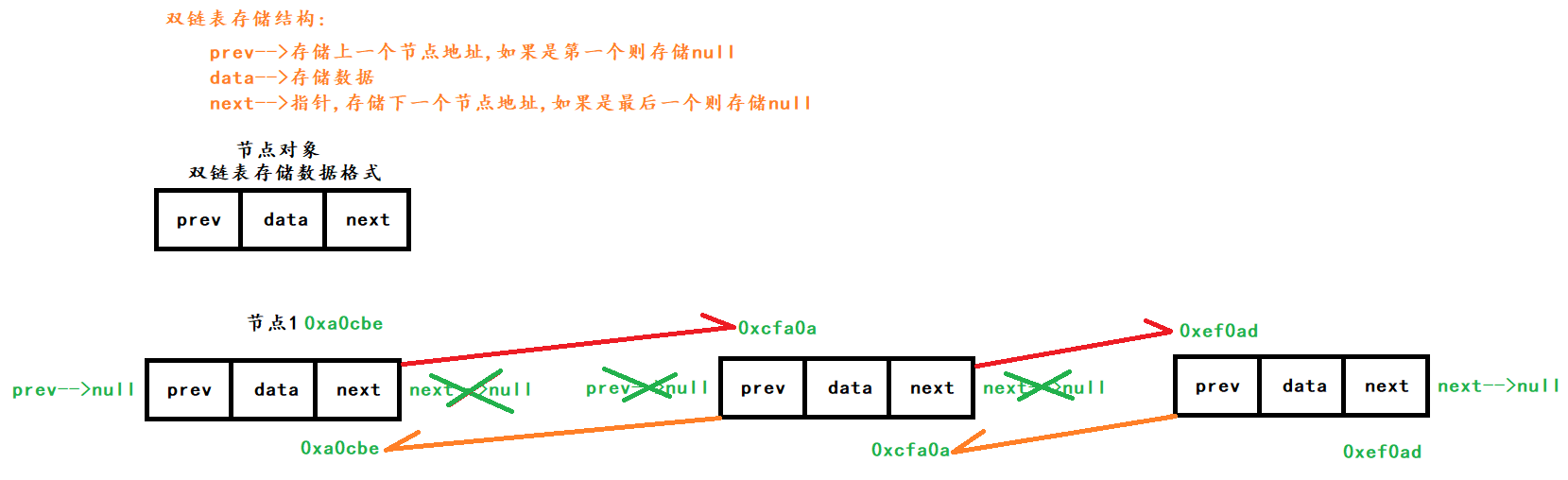
双链表
双链表结构中使用双链表存储使用节点方式(节点就是一个对象)
存储数据时有三个属性
- prev–>存储上一个节点地址,如果是第一个则存储null
- data–>存储数据
- next–>指针,存储下一个节点地址,如果是最后一个则存储null
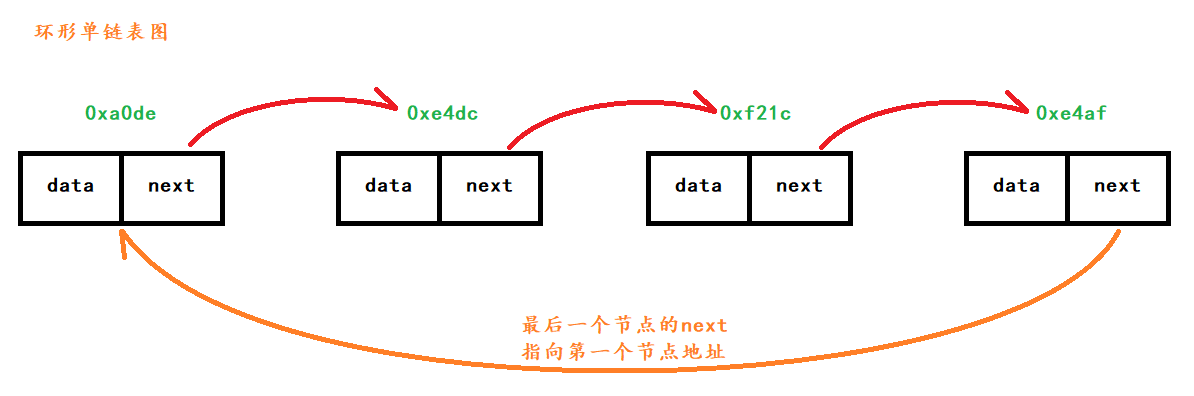
环形单链表
单链表结构:单链表存储使用节点方式(节点就是一个对象)
存储数据时有两个属性
- data(存放数据)
- next(指针,指向下一个节点地址),最后一个节点的next存储的是第一个节点的地址
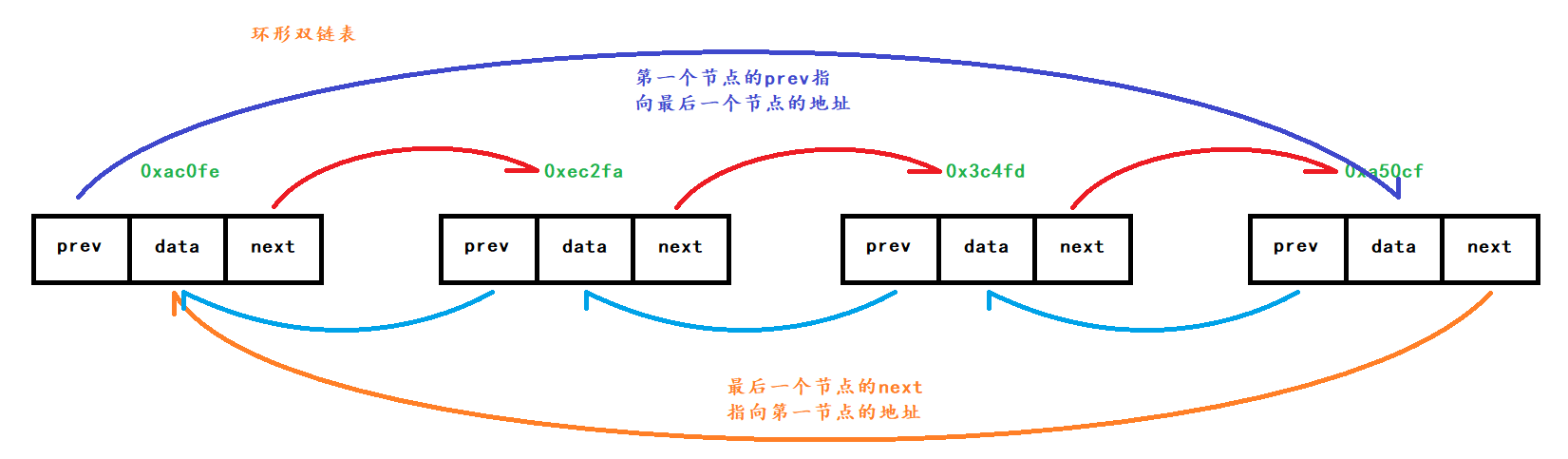
环形双链表
双链表结构:双链表存储使用节点方式(节点就是一个对象)
存储数据时有三个属性
- prev–>存储上一个节点地址,如果是第一个则存储最后一个节点的地址
- data–>存储数据
- next–>指针,存储下一个节点地址,如果是最后一个则存储第一个节点的地址
LinkedList私有的方法(自己新增针对于增加和删除方法)
public void addFirst(E e):向集合的开头插入数据public void addLast(E e):向集合的末尾插入数据public E getFirst():获取集合中的第一个元素(如果第一个元素是null则抛异常)public E getLast():获取集合中的最后一个元素(如果最后一个元素是null则抛异常)public E peekFirst():获取集合中的第一个元素但是不删除(如果第一个元素是null则返回null)public E peekLast():获取集合中的最后一个元素但是不删除(如果最后一个元素是null则返回null)public E pollFirst():获取集合中的第一个元素,获取后直接删除public E pollLast():获取集合中的最后一个元素,获取后直接删除public E removeFirst():移除集合中的第一个元素public E removeLast():移除集合中的最后一个元素
LinkedList私有的方法代码案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104public class LinkedListDemo {
public static void main(String[] args) {
// 如果使用多态方式创建则无法使用LinkedList的私有方法
// List<String> list = new LinkedList<>();
// 所以创建时只能指定自己的对象
LinkedList<String> linkedList = new LinkedList<>();
// 1. `public void addFirst(E e)`:向集合的开头插入数据
linkedList.addFirst("彭于晏");
System.out.println(linkedList);
linkedList.addFirst("梅超风");
System.out.println(linkedList);
// 2. `public void addLast(E e)`:向集合的末尾插入数据
linkedList.addLast("岳不群");
System.out.println(linkedList);
linkedList.addLast("林平之");
System.out.println(linkedList);
// 3. `public E getFirst()`:获取集合中的第一个元素
String first = linkedList.getFirst();
System.out.println(first);
// 4. `public E getLast()`:获取集合中的最后一个元素
String last = linkedList.getLast();
System.out.println(last);
// 5. `public E peekFirst()`:获取集合中的第一个元素但是不删除
String peekFirst = linkedList.peekFirst();
System.out.println(peekFirst);
// 6. `public E peekLast()`:获取集合中的最后一个元素但是不删除
String peekLast = linkedList.peekLast();
System.out.println(peekLast);
System.out.println(linkedList);
// 7. `public E pollFirst()`:获取集合中的第一个元素,获取后直接删除
String pollFirst = linkedList.pollFirst();
System.out.println(pollFirst);
// 8. `public E pollLast()`:获取集合中的最后一个元素,获取后直接删除
String pollLast = linkedList.pollLast();
System.out.println(pollLast);
System.out.println(linkedList);
// 9. `public E removeFirst()`:移除集合中的第一个元素
linkedList.addFirst("梅超风");
System.out.println(linkedList);
linkedList.removeFirst();
System.out.println(linkedList);
// 10. `public E removeLast()`:移除集合中的最后一个元素
linkedList.removeLast();
System.out.println(linkedList);
System.out.println("===============================================");
System.out.println("===============================================");
System.out.println("===============================================");
System.out.println("===============================================");
System.out.println("===============================================");
System.out.println("===============================================");
// 都是使用多态方式创建时就不存在以上的私有定义的方法
List<String> list = new LinkedList<>();
// 1. `boolean add(E e)`:向List集合中添加元素`常用`
list.add("彭于晏");
System.out.println(list);
// 2. `void add(int index, E element)`:向List集合中指定位置添加元素
list.add(0, "梅超风");
System.out.println(list);
// 3. `boolean addAll(Collection<? extends E> c)`:将指定集合中的所有元素追加到此集合的末尾
list.addAll(linkedList);
System.out.println(list);
// 4. `boolean addAll(int index, Collection<? extends E> c)`:将指定集合中的所有元素追加到此集合的指定位置
// 5. `boolean contains(Object o)`:检测此集合中是否包含指定元素`常用`
boolean isContains = list.contains("彭于晏");
System.out.println(isContains);
// 6. `boolean containsAll(Collection<?> c)`:检测集合中是否包含另一个集合中的元素
// 7. `E get(int index)`:获取集合中指定下标索引的元素并返回`常用`
String get = list.get(0);
System.out.println(get);
// 8. `E set(int index, E element)`:修改集合中指定下标索引的元素
list.set(0, "东方不败");
System.out.println(list);
// 9. `int indexOf(Object o)`:在集合中查找元素如果存在则返回此元素的下标索引(返回第一次发现的下标索引)
int indexOf = list.indexOf("彭于晏");
System.out.println(indexOf);
// 10. `int lastIndexOf(Object o)`:在集合中查找元素如果存在则返回此元素的下标索引(返回最后一次发现的下标索引)
int lastIndexOf = list.lastIndexOf("彭于晏");
System.out.println(lastIndexOf);
// 11. `List<E> subList(int fromIndex, int toIndex)`:切割集合,指定起始位置和结束位置
// 12. `ListIterator<E> listIterator()`:返回List接口迭代器
// 13. `int size()`:返回集合中的元素数量`常用`
int size = list.size();
System.out.println(size);
// 14. `boolean isEmpty()`:判断集合是否为空`常用`
System.out.println(list.isEmpty());
// 15. `Object[] toArray()`:将集合转为数组
// 16. `void clear()`:清空集合内元素
// 17. `Iterator<E> iterator()`:返回集合迭代器元素,用于遍历集合中的所有元素
// ListIterator迭代器
ListIterator<String> listIterator = list.listIterator();
while (listIterator.hasNext()) {
System.out.println(listIterator.next());
}
// Iterator迭代器
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
// 清空clear
list.clear();
System.out.println(list.isEmpty());
System.out.println(list.size());
}
}自定义实现LinkedList功能
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54public class LinkedList {
// 用于存放首节点的属性-->只记录集合中的第一个节点
private Node firstNode;
// 用于存放尾结点的属性-->只记录集合中的最后一个节点
private Node lastNode;
// 用于存放集合中的元素数量
private int size;
public boolean add(Object element) {
// 获取最后一个节点赋值给临时对象存放
Node tempNode = lastNode;
// 创建新节点,每次创建都是最后一条所以next指向直接赋值null
Node newNode = new Node(tempNode, element, null);
// 将新创建新节点当做是集合中的最后一个节点
lastNode = newNode;
// 验证临时节点是否为空
if (tempNode == null) {
// 将集合中的第一个节点的指向,指向到newNode节点上,代表是集合中的第一个节点
firstNode = newNode;
} else {
// 临时存储节点不为空则将临时节点的next指向下一个节点,下一个节点就是上面新增的
tempNode.next = newNode;
}
// 将集合中的size++代表元素数量
size++;
return true;
}
// 获取集合中的第一个节点
public Object getFirstNode() {
return firstNode.elementData;
}
// 获取集合中的最后一个节点
public Object getLastNode() {
return lastNode.elementData;
}
// size方法,获取长度
public int size() {
return size;
}
// 创建私有内部类-->节点类
private static class Node {
// 前一个节点
Node prev;
// 数据
Object elementData;
// 下一个节点
Node next;
// 全参构造方法
public Node(Node prev, Object elementData, Node next) {
this.prev = prev;
this.elementData = elementData;
this.next = next;
}
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class MyLinkedListDemo {
public static void main(String[] args) {
// 创建自定义LinkedList集合对象
LinkedList linkedList = new LinkedList();
// 添加数据
linkedList.add("彭于晏");
linkedList.add("梅超风");
linkedList.add("东方不败");
linkedList.add("岳不群");
linkedList.add("林平之");
linkedList.add("鞠婧祎");
// 获取集合中第一个元素
System.out.println(linkedList.getFirstNode());
// 获取集合中最后一个元素
System.out.println(linkedList.getLastNode());
}
}List接口之实现类Vector
Vector实现类概述
Vector与ArrayList一模一样的,唯一的区别在于Vector是线程安全的而ArrayList是线程不安全
List接口之Vector添加方法
public synchronized boolean add(E e):向集合中追加元素常用public void add(int index, E element):向集合的指定下标索引插入元素public synchronized boolean addAll(Collection<? extends E> c):将指定 Collection 中的所有元素附加到此 Vector 的末尾public synchronized boolean addAll(int index, Collection<? extends E> c):将指定 Collection 中的所有元素插入到此 Vector 的指定位置。将当前位于该位置的元素(如果有)和任何后续元素向右移动(增加它们的索引)public synchronized void addElement(E obj):向集合中追加元素
List接口之Vector删除方法
public synchronized E remove(int index):指定下标索引删除集合中元素public boolean remove(Object o):指定元素对象删除集合中的元素常用public synchronized boolean removeAll(Collection<?> c):从此 Vector 中删除包含在指定 Collection 中的所有元素public synchronized void removeAllElements():从此Vector中删除所有元素并将其大小设置为零。public synchronized boolean removeElement(Object obj):从此Vector中删除参数的第一个出现的元素。
List接口之Vector修改方法
public synchronized E set(int index, E element):修改指定下标索引的元素常用public synchronized void setElementAt(E obj, int index):修改指定下标索引的元素public synchronized void setSize(int newSize):设置集合中数组的大小
List接口之Vector查询方法
public synchronized E get(int index):通过下标索引获取集合中的数据常用public int indexOf(Object o):指定元素获取集合中是否存在如果存在则返回第一次找到的下标索引否则返回-1public synchronized int lastIndexOf(Object o):指定元素获取集合中是否存在如果存在则返回最后一次找到的下标索引否则返回-1
List接口之Vector其他方法
public synchronized int size():获取集合中的元素数量–>集合长度public synchronized boolean isEmpty():判断集合是否为空public void clear():清空集合中的所有数据
List接口之Vector代码案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71public class VectorDemo {
public static void main(String[] args) {
// 创建Vector对象
Vector<String> vector = new Vector<>();
// #### 3. List接口之Vector添加方法
// 1. `public synchronized boolean add(E e)`:向集合中追加元素`常用`
vector.add("彭于晏");
System.out.println(vector);
// 2. `public void add(int index, E element)`:向集合的指定下标索引插入元素
vector.add(0, "梅超风");
System.out.println(vector);
// 3. `public synchronized boolean addAll(Collection<? extends E> c)`:将指定 Collection 中的所有元素附加到此 Vector 的末尾
// 4. `public synchronized boolean addAll(int index, Collection<? extends E> c)`:将指定 Collection 中的所有元素插入到此 Vector 的指定位置。将当前位于该位置的元素(如果有)和任何后续元素向右移动(增加它们的索引)
// 5. `public synchronized void addElement(E obj)`:向集合中追加元素
vector.addElement("吴彦祖");
System.out.println(vector);
// #### 4. List接口之Vector删除方法
// 1. `public synchronized E remove(int index)`:指定下标索引删除集合中元素
vector.remove(0);
System.out.println(vector);
// 2. `public boolean remove(Object o)`:指定元素对象删除集合中的元素`常用`
// 3. `public synchronized boolean removeAll(Collection<?> c)`:从此 Vector 中删除包含在指定 Collection 中的所有元素
// 4. `public synchronized void removeAllElements()`:从此Vector中删除所有元素并将其大小设置为零。
// 5. `public synchronized boolean removeElement(Object obj)`:从此Vector中删除参数的第一个出现的元素。
// #### 5. List接口之Vector修改方法
// 1. `public synchronized E set(int index, E element)`:修改指定下标索引的元素`常用`
vector.set(1, "陈冠希");
System.out.println(vector);
// 2. `public synchronized void setElementAt(E obj, int index)`:修改指定下标索引的元素
// 3. `public synchronized void setSize(int newSize)`:设置集合中数组的大小
// #### 6. List接口之Vector查询方法
// 1. `public synchronized E get(int index)`:通过下标索引获取集合中的数据`常用`
String element = vector.get(0);
System.out.println(element);
// 2. `public int indexOf(Object o)`:指定元素获取集合中是否存在如果存在则返回第一次找到的下标索引否则返回-1
int indexOf = vector.indexOf("陈冠希");
System.out.println(indexOf);
// 3. `public synchronized int lastIndexOf(Object o)`:指定元素获取集合中是否存在如果存在则返回最后一次找到的下标索引否则返回-1
// #### 7. List接口之Vector其他方法
// 1. `public synchronized int size()`:获取集合中的元素数量-->集合长度
int size = vector.size();
System.out.println(size);
// 2. `public synchronized boolean isEmpty()`:判断集合是否为空
System.out.println(vector.isEmpty());
// 3. `public void clear()`:清空集合中的所有数据
vector.clear();
System.out.println(vector.isEmpty());
System.out.println(vector.size());
System.out.println("================================================");
System.out.println("================================================");
System.out.println("================================================");
System.out.println("================================================");
// 使用常用方式创建Vector对象-->多态创建
List<String> list = new Vector<>();
// 增加
list.add("舒克");
list.add("贝塔");
list.addAll(vector);
System.out.println(list);
// 删除
list.remove("陈冠希");
System.out.println(list);
// 修改
list.set(0, "开飞机的舒克");
list.set(1, "开坦克的贝塔");
// 获取数据
System.out.println(list.get(0));
System.out.println(list.get(1));
System.out.println(list);
}
}List接口的三个实现类对比
ArrayList
底层数组实现,查询速度快,增删速度慢,速度慢的原因是:每次如果插入数据则需要将插入位置之后的数据都向后移一位
线程不安全的
LinkedList
底层双链表实现,增删速度快,查询速度慢,速度慢的原因是:不管查询的是第几个都需要从头到尾查一遍
线程不安全的
Vector
- 底层数组实现,查询速度快,增删速度慢,速度慢的原因是:每次如果插入数据则需要将插入位置之后的数据都向后移一位
- 线程安全的
ArrayList和Vector实现都是相同,包括方法都是相同,唯一的区别就是ArrayList是线程不安全的,Vector是线程安全
Map接口
1. Map接口概述
Map翻译是(地图),程序中不是地图意思,Map集合存储数据是以
键(Key)值(Value)对方式,有些类似于身份证
比如:身份证是身份证号对应身份证姓名
1. 对应结果:123456789:小明
1. 身份证号:Key(键)–>身份证号是不允许重复的
2. 身份证姓名:Value(值)–>身份证姓名是允许重复的
2. 以上身份证查找时使用身份证号查找当前这个人(使用身份证号查询身份证姓名)
Map集合也是相同,Map集合使用通过Key(键)获取Value(值),并且Key(键)不允许重复,Value(值)允许重复
Map集合是java.util包中,所以也是工具类,其直接子类是HashMap/LinkedHashMap/TreeMap/HashTable/Properties等等
Map集合是无序的(Key的排序是无序的)–>虽然说无序但是有自己的排序规则,这个规则是ASCII码表如果超出127则按照Unicode码表- 无序代表
存储顺序与取出顺序不一致 - 不能同通过下标索引获取数据
2. Map接口中的常用方法
V put(K key, V value):向Map集合中添加键值对元素,不存在则添加,如果Key(键)重复则修改原有内容(不是重新添加覆盖),并返回添加的Value(值)内容- key:键
- value:值
V get(Object key):指定Key(键)获取Value(值)V remove(Object key):指定Key(键)移除Key(键)Value(值)–>移除键值对boolean containsKey(Object key):查看Map集合中是否包含指定的指定Key(键)boolean containsValue(Object value):查看Map集合中是否包含指定的Value(值)Collection<V> values():返回Map集合中的所有Value(值)boolean isEmpty():判断Map集合是否为空void clear():清空Map集合元素int size():返回Map集合的元素数量(Key-Value代表一个)Set<K> keySet():返回Map集合中的所有Key(键)值Set<Map.Entry<K, V>> entrySet():返回Map集合中的所有Key-Value–>返回所有键值对
3. map接口代码案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85public class MapDemo {
public static void main(String[] args) {
// 创建Map集合,使用其子类HashMap创建-->多态创建方式
// 常用Map泛型结构Map<String, Object>,Map<String, String>
Map<String, String> map = new HashMap<>();
// 1. `V put(K key, V value)`:向Map集合中添加键值对元素,不存在则添加,如果Key(键)重复则修改原有内容(不是重新添加),并返回添加的Value(值)内容
// 1. key:键
// 2. value:值
// map.put("772004123055", "彭于晏");
// map.put("771914123055", "聂小倩");
// map.put("771999123055", "聂小倩");
// // 771989123055是刘亦菲
// map.put("771989123055", "刘亦菲");
// 重复添加相同的Key771989123055
// 如果Key重复则修改原有的Value值,而不是覆盖Key-Value
map.put("e", "苍老师");
map.put("d", "彭于晏");
map.put("b", "聂小倩");
map.put("c", "聂小倩");
// 771989123055是刘亦菲
map.put("a", "刘亦菲");
// 重复添加相同的Key771989123055
// 如果Key重复则修改原有的Value值,而不是覆盖Key-Value
map.put("f", "苍老师");
System.out.println(map);
// 1. `V get(Object key)`:指定Key(键)获取Value(值)
String value = map.get("a");
System.out.println(value);
// 获取没有的值时是报错还是返回null?
value = map.get("aa");
System.out.println(value);
// 第二个getOrDefault,当获取的key不存在时返回defaultValue-->返回设置默认值
value = map.getOrDefault("a", "不存在");
System.out.println(value);
value = map.getOrDefault("aa", "不存在");
System.out.println(value);
System.out.println("======================================================");
// 2. `V remove(Object key)`:指定Key(键)移除`Key(键)Value(值)`-->移除键值对
String remove = map.remove("a");
System.out.println(remove);
System.out.println(map);
// 3. `boolean containsKey(Object key)`:查看Map集合中是否包含指定的指定Key(键)
System.out.println("======================================================");
boolean isContainsKey = map.containsKey("f");
System.out.println(isContainsKey);
isContainsKey = map.containsKey("ff");
System.out.println(isContainsKey);
// 4. `boolean containsValue(Object value)`:查看Map集合中是否包含指定的Value(值)
System.out.println("======================================================");
boolean isContainsValue = map.containsValue("苍老师");
System.out.println(isContainsValue);
isContainsValue = map.containsValue("小泽老师");
System.out.println(isContainsValue);
// 5. `Collection<V> values()`:返回Map集合中的所有Value(值)
Collection<String> values = map.values();
System.out.println(values);
// 6. `boolean isEmpty()`:判断Map集合是否为空
System.out.println(map.isEmpty());
// 8. `int size()`:返回Map集合的元素数量(Key-Value代表一个)
System.out.println(map.size());
// Map集合的遍历只能通过keySet和entrySet遍历
// 9. `Set<K> keySet()`:返回Map集合中的所有Key(键)值
System.out.println("======================================================");
Set<String> keySet = map.keySet();
// 使用增强for循环遍历keySet
for (String key : keySet) {
// 遍历key并使用key获取value
System.out.println("key:" + key + ",value:" + map.get(key));
}
// 10. `Set<Map.Entry<K, V>> entrySet()`:返回Map集合中的所有Key-Value-->返回所有键值对
// Map.Entry-->Entry是Map接口中的内部接口,作用就是返回Map集合中的Key-Value-->返回键值对
// Entry接口中有两个方法,一个getKey(获取key)一个是getValue(获取value)
System.out.println("======================================================");
Set<Map.Entry<String, String>> entrySet = map.entrySet();
// 遍历Set集合
for (Map.Entry<String, String> entry : entrySet) {
// 打印结果
System.out.println("key:" + entry.getKey() + ",value:" + entry.getValue());
}
// 7. `void clear()`:清空Map集合元素
map.clear();
System.out.println(map);
System.out.println(map.size());
}
}Map接口之HashMap类
1. HashMap概述
HashMap采用哈希算法实现,是Map接口中最常用的实现类,底层实现是使用哈希表存储数据,所以Key不允许重复,如果重复则修改Value值,HashMap在查找,删除,修改方法中效率非常高(全能增删改查效率都快)
HashMap的哈希表这种数据结构非常重要,并且应用场景非常的丰富,所以概念得懂- 哈希表是嘛玩意儿?
- 哈希表是基于链表实现,是链表的升级版本
- 哈希表,数组,链表的优劣势
- 数组:
- 优势:查询速度快,可以直接指定下标索引查询
- 劣势:增删速度慢,增加或删除时需要将当前位置之后的所有元素向后移动
- 链表:
- 优势:增删速度快,原因是元素都是使用指向方式指向地址,不存在连续空间,想删除哪个直接删掉,并将前后的元素在相互关联,不用移动元素的位置
- 劣势:查询速度慢,因为没有连续空间,每一个元素知道的只有他的前一个节点和后一个节点是谁,不知道其他节点是谁,只能通过从头遍历到尾的方式查询
- 哈希表:是吸取
数组与链表的有点和缺点产生- 取长补短进行改进,改进后有
数组+链表方式产生了哈希表的数据结构,全能增删改查效率都快(但是跟数组比起来还是差点意思的)
- 取长补短进行改进,改进后有
- 数据结构的存储方式分为两种
- 顺序存储结构–>数组
- 链式存储结构–>链表
- 数组:
2. 哈希表概述
哈希表是由
数组+链表实现1. 二叉树
1. 二叉树是树形结构,使用的非常多,一般般情况使用时是针对于结构进行升级以及使用算法计算如何分叉,由一个节点及两根互不相交的分叉来作为左子树和右子树,实现时分为5种形态 2. 五种二叉树形态  1. 第一种情况:空树 2. 第二种情况:仅有一个节点的二叉树 3. 第三种情况:仅有左子树的二叉树 4. 第四种情况:仅有右子树的二叉树 5. 第五种情况:有左右子树的非空二叉树(完整二叉树) 2. 二叉树是如何排序的 1. 分为左右子树,左子树数字小于上一个节点,右子树数字大于上一个节点 2. 例如有这么一组数据-->25,14,27,21,19,26  3. 二叉树实现了排序功能可以快速的检索,但是如果本身数据是有序的(例如:6,5,4,3,2,1)那么这种数据就会倾倒式的一边倒,要么向左要么向右-->一旦发生这种情况那就是普通的链表结构了 4. 二叉树的缺点是不能排序顺序数字的结构,一旦排序则变回普通的链表结构例如:数据为(1,2,3,4,5,6) 2. 平衡二叉树
为了避免二叉树出现的一边倒的情况,科学家研究除了平衡二叉树,比如在原有的数据将数据进行平衡,会将一组数据的排序方式改变,当前已知的是不管怎么排序是不会出现一边倒超出两个及以上节点的情况,但是排序时次数是不确定,当前有可能排序次数早很多次的情况,如果出现不平排序次数不确定,有可能会重新将所有的数据进行排序,造成速度慢情况
缺点是如果出现了添加的元素过多时他的排序次数是不确定的,有可能会出现重新排列所有的情况,可能会造成效率低多做无用功的操作,有问题则需要解决–>科学家又研究除了一个叫做红黑二叉树的结构3. 红黑二叉树
红黑二叉树是为了解决平衡二叉树造成的不确定移动次数的情况,升级版本;红黑二叉树又被称之为
红黑树,是有二叉树组成,同时有事一颗自平衡排序二叉树- 红黑树在原有的平衡二叉树基础上升级了几个特点
- 每个节点要么是
红色,要么是黑色 - 根节点始终保持
黑色 - 所有的叶子节点都是为空节点–>null,并且全是
黑色 - 每个
红色节点的两个子节点都是黑色,但是每个叶子到根的路径上不会出现两个连续的红色节点 - 从任意节点到子节点中的每个叶子节点的路径可以包含相同数量的黑色节点
- 每个节点要么是
通过以上的升级得出最终的结论就是红黑树有两个颜色,黑色允许重复,红色不允许重复(上下节点)
红黑树的操作:插入删除,左旋,右旋,着色,每次插入或删除一个节点时都可能会导致不符合规范的情况(超出两个节点的范围了),红黑树就进行修复,使用左旋与右旋和着色操作进行修复,用于保持红黑树的结构始终平衡
红黑树动画演示页面:https://www.cs.usfca.edu/~galles/visualization/RedBlack.html4. 二叉树/平衡二叉树/红黑二叉树
- 二叉树基于链表,为了解决链表的查询问题而生,存在的问题,如果数据是递增的则会出现一边倒的情况,相当于最终还是链表结构,不是二叉树结构梁
- 平衡二叉树基于二叉树为了解决出现一边倒的情况而生,排序时会根据数据的结构进行自动平衡(不会超过2个多节点,一旦超过则重新排序),但是也有问题,如果数据过多在排序过程中容易出现整体排序(无法确定排序次数)可能造成影响性能的问题
- 红黑二叉树基于平衡二叉树,是升级版本,为了解决平衡二叉树排序过程中出现未知排序次数造成的性能问题而生,使用
红/黑两色用于进行标识,并且永远不会出现连续的红色,黑色是会出现连续情况,并且黑色始终都会比红色多
3. Hash Map构造方法
1
2
3
4
5
6
7
8// 使用空参构造方法创建Map集合,会有默认容量
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
// 指定初始化容量创建Map集合
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}4. HashMap常用方法–>由于HashMap使用的都是他爹Map接口的方法,所以方法一致
V put(K key, V value):向Map集合中添加键值对元素,不存在则添加,如果Key(键)重复则修改原有内容(不是重新添加覆盖),并返回添加的Value(值)内容- key:键
- value:值
V get(Object key):指定Key(键)获取Value(值)V remove(Object key):指定Key(键)移除Key(键)Value(值)–>移除键值对boolean containsKey(Object key):查看Map集合中是否包含指定的指定Key(键)boolean containsValue(Object value):查看Map集合中是否包含指定的Value(值)Collection<V> values():返回Map集合中的所有Value(值)boolean isEmpty():判断Map集合是否为空void clear():清空Map集合元素int size():返回Map集合的元素数量(Key-Value代表一个)Set<K> keySet():返回Map集合中的所有Key(键)值Set<Map.Entry<K, V>> entrySet():返回Map集合中的所有Key-Value–>返回所有键值对
5. HashMap集合代码案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85public class MapDemo {
public static void main(String[] args) {
// 创建Map集合,使用其子类HashMap创建-->多态创建方式
// 常用Map泛型结构Map<String, Object>,Map<String, String>
Map<String, String> map = new HashMap<>();
// 1. `V put(K key, V value)`:向Map集合中添加键值对元素,不存在则添加,如果Key(键)重复则修改原有内容(不是重新添加),并返回添加的Value(值)内容
// 1. key:键
// 2. value:值
// map.put("772004123055", "彭于晏");
// map.put("771914123055", "聂小倩");
// map.put("771999123055", "聂小倩");
// // 771989123055是刘亦菲
// map.put("771989123055", "刘亦菲");
// 重复添加相同的Key771989123055
// 如果Key重复则修改原有的Value值,而不是覆盖Key-Value
map.put("e", "苍老师");
map.put("d", "彭于晏");
map.put("b", "聂小倩");
map.put("c", "聂小倩");
// 771989123055是刘亦菲
map.put("a", "刘亦菲");
// 重复添加相同的Key771989123055
// 如果Key重复则修改原有的Value值,而不是覆盖Key-Value
map.put("f", "苍老师");
System.out.println(map);
// 1. `V get(Object key)`:指定Key(键)获取Value(值)
String value = map.get("a");
System.out.println(value);
// 获取没有的值时是报错还是返回null?
value = map.get("aa");
System.out.println(value);
// 第二个getOrDefault,当获取的key不存在时返回defaultValue-->返回设置默认值
value = map.getOrDefault("a", "不存在");
System.out.println(value);
value = map.getOrDefault("aa", "不存在");
System.out.println(value);
System.out.println("======================================================");
// 2. `V remove(Object key)`:指定Key(键)移除`Key(键)Value(值)`-->移除键值对
String remove = map.remove("a");
System.out.println(remove);
System.out.println(map);
// 3. `boolean containsKey(Object key)`:查看Map集合中是否包含指定的指定Key(键)
System.out.println("======================================================");
boolean isContainsKey = map.containsKey("f");
System.out.println(isContainsKey);
isContainsKey = map.containsKey("ff");
System.out.println(isContainsKey);
// 4. `boolean containsValue(Object value)`:查看Map集合中是否包含指定的Value(值)
System.out.println("======================================================");
boolean isContainsValue = map.containsValue("苍老师");
System.out.println(isContainsValue);
isContainsValue = map.containsValue("小泽老师");
System.out.println(isContainsValue);
// 5. `Collection<V> values()`:返回Map集合中的所有Value(值)
Collection<String> values = map.values();
System.out.println(values);
// 6. `boolean isEmpty()`:判断Map集合是否为空
System.out.println(map.isEmpty());
// 8. `int size()`:返回Map集合的元素数量(Key-Value代表一个)
System.out.println(map.size());
// Map集合的遍历只能通过keySet和entrySet遍历
// 9. `Set<K> keySet()`:返回Map集合中的所有Key(键)值
System.out.println("======================================================");
Set<String> keySet = map.keySet();
// 使用增强for循环遍历keySet
for (String key : keySet) {
// 遍历key并使用key获取value
System.out.println("key:" + key + ",value:" + map.get(key));
}
// 10. `Set<Map.Entry<K, V>> entrySet()`:返回Map集合中的所有Key-Value-->返回所有键值对
// Map.Entry-->Entry是Map接口中的内部接口,作用就是返回Map集合中的Key-Value-->返回键值对
// Entry接口中有两个方法,一个getKey(获取key)一个是getValue(获取value)
System.out.println("======================================================");
Set<Map.Entry<String, String>> entrySet = map.entrySet();
// 遍历Set集合
for (Map.Entry<String, String> entry : entrySet) {
// 打印结果
System.out.println("key:" + entry.getKey() + ",value:" + entry.getValue());
}
// 7. `void clear()`:清空Map集合元素
map.clear();
System.out.println(map);
System.out.println(map.size());
}
}6. HashMap的实现是什么?
1. HashMapJDK1.7跟JDK1.8的切换
红黑树原码分析- HashMap的实现JDK1.7跟JDK1.8不同,JDK1.7中HashMap是使用
数组加链表的结合体实现,JDK1.8是数组加链表加红黑树实现,JDK1.7之前只能使用数组加链表的实现,JDK1.8后在数据量少的时候使用的是数组加链表实现,而当数组存储到8个长度时则更改为数组加红黑树实现 - 查看HashMap具体实现–>put方法,什么时候用数组加链表,什么时候用数组加红黑树,以及为什么Key不能重复是如何实现的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94// 是否使用红黑树的阈值-->如果长度是在8以内,使用的是JDK1.8的数组加链表,如果是8以上则使用数组加红黑树
static final int TREEIFY_THRESHOLD = 8;
// HashMap的普通方法
public V put(K key, V value) {
// 调用putVal方法
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 循环验证当前数组中的数据是有多少
for (int binCount = 0; ; ++binCount) {
// 将p.next指向的地址赋值给e变量,并判断是否为null
if ((e = p.next) == null) {
// 如果为null则进入
// 调用newNode方法创建新节点,并赋值给p.next代表上一个节点的指向位置,最后一个节点
p.next = newNode(hash, key, value, null);
// 用循环判断当前二叉树统计的次数是否大于等于7
if (binCount >= TREEIFY_THRESHOLD - 1)
// 如果binCount大于等于7则代表当前存的数据已经是8条,调用treeifyBin方法使用红黑树
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
// 上方判断如果大于等于7则使用红黑树的代码
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
// 创建的就是红黑树
TreeNode<K,V> hd = null, tl = null;
do {
// 真实创建红黑树并赋值
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
// 红黑树内部类
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
// parent是红黑树的父级连接
TreeNode<K,V> parent; // red-black tree links
// left是红黑树的左子树
TreeNode<K,V> left;
// right是红黑树的右子树
TreeNode<K,V> right;
// prev用于连接节点,有利于删除
TreeNode<K,V> prev; // needed to unlink next upon deletion
// red用于记录当前节点是红树还是黑树
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
// ...省略n行实现代码
}2. HashMap的put方法为何不能添加重复的key源码分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
// 声明Node节点数组
HashMap.Node<K, V>[] tab;
// 声明Node节点对象
HashMap.Node<K, V> p;
// 声明两个int变量
int n, i;
// 将table数据赋值给tab然后判断是否等于null
// 如果tab不等于null则讲tab.length赋值n变量,然后判断是否为0
if ((tab = table) == null || (n = tab.length) == 0)
// 重新设置长度--》然后创建对象并返回
// 返回对象后又获取数组的长度-->赋值给n
n = (tab = resize()).length;
// hash是调用方法计算而来
// 讲n数组长度-1,并使用按位与hash计算,将最终的值赋值给i(赋值后如果数字相同则直接向后继续添加)
// tab[i = (n - 1) & hash]-->例如key是name,最终计算出的值为8,讲数组下标为8的数据取出
// p-->Node节点对象,判断是否等于null
if ((p = tab[i = (n - 1) & hash]) == null)
// 如果等于null创建Node节点对象赋值进去
tab[i] = newNode(hash, key, value, null);
else {
// 声明了一个Node节点对象e
HashMap.Node<K, V> e;
// Key的泛型名称
K k;
// p.hash == hash下一行是解释
// p.hash是当前tab[i]Node数组下标中的值,hash是传入的Key值如果相同则代表当前他们可能是相同数据
// (k = p.key) == key--》基本数据类型
// 将tab[i]Node数组下标中的值--》p.key=原本可能存在的key,与传入的key对比(基本数据类型)
// key != null && key.equals(k)
// 先验证传入的key是否为null如果不是则使用key.equals()对比内容是否相同
// 这里是验证传入Key是否已存在的根本位置
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
// 用p节点赋值给e节点
e = p;
else if (p instanceof HashMap.TreeNode)
e = ((HashMap.TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);
else {
// 如果hash相同而equals不同则进入这里执行
for (int binCount = 0; ; ++binCount) {
// p.next-->指向的下一个节点赋值给e
if ((e = p.next) == null) {
// 将创建的新节点地址赋值给p.next的指向
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 与上面的验证相同
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 验证e节点是否不为null
if (e != null) {
// 将value赋值给oldValue(老值)
V oldValue = e.value;
// 判断oldValue是否为null
// 是put方法调用的传入的值,传入默认就是false
if (!onlyIfAbsent || oldValue == null)
// 将调用put时传入的值直接赋值给e.value
e.value = value;
// 这个方法就是将e节点对象重新赋值到节点数组中
afterNodeAccess(e);
// 返回修改前的值
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}Map接口之LinkedHashMap类
1. LinkedHashMap类概述
LinkedHashMap类与HashMap相同,唯一不同点在于他底层是采用的
链表+哈希表结构,由于是链表实现所以他的元素顺序能够保证(有序的:存入数据与取出顺序相同),其他的实现与HashMap基本完全一致,同样key也是不允许重复,LinkedHashMap类是继承自HashMap类的2. LinkedHashMap类的构造方法
1
2
3
4
5
6
7
8
9
10
11
12// 创建LinkedHashMap集合对象,使用默认长度
public LinkedHashMap() {
// 调用他爹HashMap的构造方法
super();
accessOrder = false;
}
// 创建LinkedHashMap集合对象并指定初始容量
public LinkedHashMap(int initialCapacity) {
// 调用他爹HashMap构造方法
super(initialCapacity);
accessOrder = false;
}3. LinkedHashMap类的常用方法(由于是直接继承自HashMap类的所以很多方法都是用的他爹的)
V put(K key, V value):向Map集合中添加键值对元素,不存在则添加,如果Key(键)重复则修改原有内容(不是重新添加覆盖),并返回添加的Value(值)内容- key:键
- value:值
V get(Object key):指定Key(键)获取Value(值)V remove(Object key):指定Key(键)移除Key(键)Value(值)–>移除键值对boolean containsKey(Object key):查看Map集合中是否包含指定的指定Key(键)boolean containsValue(Object value):查看Map集合中是否包含指定的Value(值)Collection<V> values():返回Map集合中的所有Value(值)boolean isEmpty():判断Map集合是否为空void clear():清空Map集合元素int size():返回Map集合的元素数量(Key-Value代表一个)Set<K> keySet():返回Map集合中的所有Key(键)值Set<Map.Entry<K, V>> entrySet():返回Map集合中的所有Key-Value–>返回所有键值对
4. LinkedHashMap类代码案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45public class LinkedHashMapDemo {
public static void main(String[] args) {
// 创建 LinkedHashMap类 对象-->多态方式创建
Map<String, Object> map = new LinkedHashMap<>();
// 1. `V put(K key, V value)`:向Map集合中添加键值对元素,不存在则添加,如果Key(键)重复则修改原有内容(不是重新添加覆盖),并返回添加的Value(值)内容`常用掌握`
// 1. key:键
// 2. value:值
map.put("name", "彭于晏");
map.put("age", 18);
map.put("sex", "男神");
// 赋值一个相同的
map.put("name", "吴彦祖");
map.put("abc", "abc");
System.out.println(map);
// 1. `V get(Object key)`:指定Key(键)获取Value(值)`常用掌握`
Object name = map.get("name");
System.out.println(name);
// 2. `V remove(Object key)`:指定Key(键)移除`Key(键)Value(值)`-->移除键值对
Object abc = map.remove("abc");
System.out.println(abc);
System.out.println(map);
// 3. `boolean containsKey(Object key)`:查看Map集合中是否包含指定的指定Key(键)
System.out.println(map.containsKey("name"));
// 4. `boolean containsValue(Object value)`:查看Map集合中是否包含指定的Value(值)
System.out.println(map.containsValue("吴彦祖"));
// 5. `Collection<V> values()`:返回Map集合中的所有Value(值)
Collection<Object> values = map.values();
System.out.println(values);
// 6. `boolean isEmpty()`:判断Map集合是否为空
System.out.println(map.isEmpty());
// 8. `int size()`:返回Map集合的元素数量(Key-Value代表一个)`常用掌握`
System.out.println(map.size());
// 9. `Set<K> keySet()`:返回Map集合中的所有Key(键)值
Set<String> strings = map.keySet();
System.out.println(strings);
// 10. `Set<Map.Entry<K, V>> entrySet()`:返回Map集合中的所有Key-Value-->返回所有键值对
Set<Map.Entry<String, Object>> entries = map.entrySet();
System.out.println(entries);
// 7. `void clear()`:清空Map集合元素
map.clear();
// 打印数组长度以及是否为空
System.out.println(map.size());
System.out.println(map.isEmpty());
}
}Map接口之Hashtable类
1. Hashtable类概述
Hashtable类与HashMap类方法及构造方法基本都是相同的,底层依旧是采用
数组+链表或数组+红黑树,增删改查速度也很快,唯一的区别在于Hashtable是线程安全的(使用了synchronized关键字修饰),HashMap是线程不安全的2. Hashtable类的构造方法
1
2
3
4
5
6
7
8// 创建Hashtable集合对象,默认容量是11
public Hashtable() {
this(11, 0.75f);
}
// 创建HashTable集合对象,并指定初始化容量
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}3. Hashtable类的常用方法
public synchronized V put(K key, V value):向集合中添加元素- key:键值
- value:值
public synchronized V get(Object key):通过key获取集合中指定value值public synchronized V remove(Object key):通过key移除集合中的元素public Set<K> keySet():获取集合中的所有key值public Collection<V> values():获取集合中所有值public Set<Map.Entry<K,V>> entrySet():获取集合中所有键值对(key-value)public synchronized int size():获取集合中所有元素数量public synchronized boolean isEmpty():判断集合是否为空public synchronized void clear():清空集合元素
4. Hashtable类代码案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37public class HashTableDemo {
public static void main(String[] args) {
// 创建HashTable对象
Map<String, Object> map = new Hashtable<>();
// 1. `public synchronized V put(K key, V value)`:向集合中添加元素
// 1. key:键值
// 2. value:值
map.put("name", "小泽老师");
map.put("age", 40);
map.put("sex", "女");
map.put("nation", "小日子过的不错的国家");
System.out.println(map);
// 2. `public synchronized V get(Object key)`:通过key获取集合中指定value值
System.out.println(map.get("name"));
// 3. `public synchronized V remove(Object key)`:通过key移除集合中的元素
System.out.println(map);
System.out.println(map.remove("nation"));
System.out.println(map);
// 4. `public Set<K> keySet()`:获取集合中的所有key值
Set<String> strings = map.keySet();
System.out.println(strings);
// 5. `public Collection<V> values()`:获取集合中所有值
Collection<Object> values = map.values();
System.out.println(values);
// 6. `public Set<Map.Entry<K,V>> entrySet()`:获取集合中所有键值对(key-value)
Set<Map.Entry<String, Object>> entries = map.entrySet();
System.out.println(entries);
// 7. `public synchronized int size()`:获取集合中所有元素数量
System.out.println(map.size());
// 8. `public synchronized boolean isEmpty()`:判断集合是否为空
System.out.println(map.isEmpty());
// 9. `public synchronized void clear()`:清空集合元素
map.clear();
System.out.println(map.size());
System.out.println(map.isEmpty());
}
}Map接口之TreeMap类
1. TreeMap类概述
TreeMap底层使用红黑树实现,与HashMap的却别是不在验证长度更改红黑树,其他与HashMap相同
2. TreeMap类的构造方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14// 创建TreeMap集合对象
public TreeMap() {
// comparator是比较器,比较器的作用是 用于排序
comparator = null;
}
// 创建TreeMap集合对象,并指定Map集合将数据添加至TreeMap集合中
public TreeMap(Map<? extends K, ? extends V> m) {
comparator = null;
putAll(m);
}
// 创建TreeMapper集合对象并指定比较器
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}3. TreeMap类的常用方法
public V put(K key, V value):向集合中添加数据- key:键值
- value:值
public void putAll(Map<? extends K, ? extends V> map):添加整个Map集合的数据public V get(Object key):指定key获取集合中的value值public K firstKey():获取集合中第一个元素的keypublic K lastKey():获取集合中最后一个元素的keypublic boolean containsKey(Object key):判断集合中是否包含指定keypublic boolean containsValue(Object value):判断集合中是否包含指定valuepublic Set<K> keySet():取出集合中所有的key值public Collection<V> values():取出集合中所有的value值public Set<Map.Entry<K,V>> entrySet():取出集合中所有的key-value(取出键值对)public V remove(Object key):指定key移除集合中的元素public int size():获取集合中添加的元素数量boolean isEmpty():获取集合是否为空public void clear():清空集合中所有的元素
4. TreeMap集合代码案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48public class TreeMapDemo {
public static void main(String[] args) {
// 使用多态方式创建TreeMap集合对象
Map<String, Object> map = new TreeMap<>();
// 1. `public V put(K key, V value)`:向集合中添加数据
// 1. key:键值
// 2. value:值
map.put("name", "彭于晏");
map.put("age", 18);
map.put("sex", "男神");
// 赋值一个相同的
map.put("name", "吴彦祖");
System.out.println(map);
// 2. `public void putAll(Map<? extends K, ? extends V> map)`:添加整个Map集合的数据
map.putAll(map);
// 3. `public V get(Object key)`:指定key获取集合中的value值
System.out.println(map.get("name"));
// 一下两个方法是TreeMap私有方法所以需要向下转型
TreeMap<String, Object> treeMap = (TreeMap<String, Object>) map;
// 4. `public K firstKey()`:获取集合中第一个元素的key
System.out.println(treeMap.firstKey());
// 5. `public K lastKey()`:获取集合中最后一个元素的key
System.out.println(treeMap.lastKey());
// 6. `public boolean containsKey(Object key)`:判断集合中是否包含指定key
System.out.println(map.containsKey("name"));
// 7. `public boolean containsValue(Object value)`:判断集合中是否包含指定value
System.out.println(map.containsValue("吴彦祖"));
// 8. `public Set<K> keySet()`:取出集合中所有的key值
Set<String> strings = map.keySet();
System.out.println(strings);
// 9. `public Collection<V> values()`:取出集合中所有的value值
Collection<Object> values = map.values();
System.out.println(values);
// 10. `public Set<Map.Entry<K,V>> entrySet()`:取出集合中所有的key-value(取出键值对)
Set<Map.Entry<String, Object>> entries = map.entrySet();
System.out.println(entries);
// 11. `public V remove(Object key)`:指定key移除集合中的元素
System.out.println(map.remove("sex"));
// 12. `public int size()`:获取集合中添加的元素数量
System.out.println(map.size());
// 13. `boolean isEmpty()`:获取集合是否为空
System.out.println(map.isEmpty());
// 14. `public void clear()`:清空集合中所有的元素
map.clear();
System.out.println(map.size());
System.out.println(map.isEmpty());
}
}Set接口
1. Set接口概述
Set接口与List接口相同都是Collection接口的子孙接口,Set接口中没有新增方法(所有的方法都是他爹的Collection接口的),之前所用的List接口的方法在Set接口中也是通用的
Set接口特点:数据不重复,顺序是无序的(添加顺序与取出顺序不同,以及没有下标指向)无索引,遍历只能通过循环遍历(数据不能重复的原因是使用的HashMap类的put方法)2. Set接口方法–>与他父类Collection接口一致
boolean add(E e):向集合中添加元素boolean addAll(Collection<? extends E> c):向集合中添加一个集合元素boolean contains(Object o):检测集合中是否包含某个元素boolean containsAll(Collection<?> c):检测集合中是否包含另一个集合中的元素boolean remove(Object o):从集合中移除指定数据(对象)boolean removeAll(Collection<?> c):移除此集合的所有也包含在指定集合中的元素boolean retainAll(Collection<?> c):移除刺激和的所有不包含在指定集合中的元素(移除非相同的元素,非交集元素)int size():返回集合中的元素数量boolean isEmpty():判断集合是否为空Object[] toArray():将集合转为数组void clear():清空集合内元素Iterator<E> iterator():返回集合迭代器元素,用于遍历集合中的所有元素
Set接口之HashSet类
1. HashSet类概述
HashSet底层使用哈希表算法实现,底层实际是使用
HashMap的put方法实现,所以本质HashMap是HashSet类的母亲,HashSet有些类似于野孩子,谁的方法都有2. HashSet类使用HashMap类的实现
1
2
3
4
5
6
7
8
9
10
11public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable {
// 声明HashMap类对象,在创建HashSet对象时创建
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
// 创建HashSet对象
public HashSet() {
// 顺带着创建了HashMap集合对象
map = new HashMap<>();
}
}3. HashSet类的构造方法
1
2
3
4
5
6
7
8
9
10// 使用空参构造方法创建HashSet集合对象,并在内部创建HashMap集合对象
public HashSet() {
// 创建HashMap集合对象
map = new HashMap<>();
}
// 使用带参构造方法创建HashSet集合对象
public HashSet(int initialCapacity) {
// 创建HashMap集合对象并初始化容量
map = new HashMap<>(initialCapacity);
}4. HashSet类的常用方法
public boolean add(E e):向集合中添加元素方法boolean addAll(Collection<? extends E> c):向集合中添加指定集合的所有数据public boolean contains(Object o):判断集合中是否包含某一个指定的元素public boolean remove(Object o):从集合中移除指定元素,如果成功则返回true,否则返回falsepublic int size():返回集合中元素数量public boolean isEmpty():判断集合是否为空public Iterator<E> iterator():返回此集合的迭代器对象public void clear():移除集合中所有的元素
5. HashSet类的代码案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45public static void main(String[] args) {
// 创建HashSet集合对象
Set<String> set = new HashSet<>();
// 1. `public boolean add(E e)`:向集合中添加元素方法
set.add("彭于晏");
set.add("吴彦祖");
set.add("梅超风");
set.add("灭绝师太");
set.add("川建国");
set.add("基尼太美");
set.add("古校长");
set.add("彭于晏");
System.out.println(set);
// 2. `boolean addAll(Collection<? extends E> c)`:向集合中添加指定集合的所有数据
List<String> list = new ArrayList<>();
list.add("彭于晏");
list.add("古校长");
list.add("古天乐");
list.add("渣渣辉");
list.add("小泽老师");
set.addAll(list);
System.out.println(set);
// 3. `public boolean contains(Object o)`:判断集合中是否包含某一个指定的元素
System.out.println(set.contains("灭绝师太"));
// 4. `public boolean remove(Object o)`:从集合中移除指定元素,如果成功则返回true,否则返回false
System.out.println(set.remove("基尼太美"));
System.out.println(set.remove("基尼太美"));
System.out.println(set);
// 5. `public int size()`:返回集合中元素数量
System.out.println(set.size());
// 6. `public boolean isEmpty()`:判断集合是否为空
System.out.println(set.isEmpty());
System.out.println("==================================");
// 7. `public Iterator<E> iterator()`:返回此集合的迭代器对象
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
// 8. `public void clear()`:移除集合中所有的元素
System.out.println("调用clear方法");
set.clear();
System.out.println(set);
System.out.println(set.isEmpty());
}
}6. HashSet中都是如何实现的方法
HashSet的方法没有一个是自己写的,要么是继承自AbstractSet抽象类,要么就是直接调用HashMap的方法
1. 所以HashSet为什么不允许重复值就是因为调用的HashMap的put方法,而put放中有验证(hashCode和equals)
1
2
3
4
5
6// 仅仅只是一个方法举例子,其他的相同!
// HashSet类中的add方法
public boolean add(E e) {
// HashSet什么事儿都没做直接调用map.put()设置值
return map.put(e, PRESENT)==null;
}21. Set接口之TreeSet
1. TreeSet类的概述
TreeSet底层实现是基于TreeMap类的,TreeMap与HashSet相同,没有自己独立的方法,所以本质也是数组TreeMap类
2. TreeSet类的构造方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 使用空参构造方法创建TreeSet对象
public TreeSet() {
// 调用带参构造方法创建一个TreeMap对象
this(new TreeMap<E,Object>());
}
// 使用指定collection集合创建TreeSet对象
public TreeSet(Collection<? extends E> c) {
// 调用空参构造方法
this();
// 调用addAll方法添加集合
addAll(c);
}
// 创建带有比较器的TreeSet对象
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}3. TreeSet类的常用方法
public boolean add(E e):向集合中添加元素方法boolean addAll(Collection<? extends E> c):向集合中添加指定集合的所有数据public boolean contains(Object o):判断集合中是否包含某一个指定的元素public boolean remove(Object o):从集合中移除指定元素,如果成功则返回true,否则返回falsepublic int size():返回集合中元素数量public boolean isEmpty():判断集合是否为空public Iterator<E> iterator():返回此集合的迭代器对象public void clear():移除集合中所有的元素
4. TreeSet类的代码案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46public class TreeSetDemo {
public static void main(String[] args) {
// 使用多态方式创建TreeSet集合
Set<String> set = new TreeSet<>();
// 1. `public boolean add(E e)`:向集合中添加元素方法
set.add("蜘蛛侠");
set.add("黑寡妇");
set.add("绿巨人");
set.add("美国翘臀");
set.add("死侍");
set.add("死侍");
System.out.println(set);
// 2. `boolean addAll(Collection<? extends E> c)`:向集合中添加指定集合的所有数据
List<String> list = new ArrayList<>();
list.add("超人");
list.add("蝙蝠侠");
list.add("钢骨");
list.add("神奇女侠");
list.add("海王");
list.add("海王");
list.add("火星猎人");
System.out.println(list);
set.addAll(list);
System.out.println(set);
// 3. `public boolean contains(Object o)`:判断集合中是否包含某一个指定的元素
System.out.println(set.contains("黑寡妇"));
// 4. `public boolean remove(Object o)`:从集合中移除指定元素,如果成功则返回true,否则返回false
System.out.println(set.remove("火星猎人"));
System.out.println(set.remove("火星猎人"));
System.out.println(set);
// 5. `public int size()`:返回集合中元素数量
System.out.println(set.size());
// 6. `public boolean isEmpty()`:判断集合是否为空
System.out.println(set.isEmpty());
// 7. `public Iterator<E> iterator()`:返回此集合的迭代器对象
System.out.println("==========================================");
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
// 8. `public void clear()`:移除集合中所有的元素
System.out.println("调用clear方法");
set.clear();
System.out.println(set);
}
}5. TreeSet类的具体实现
TreeSet与HashSet相同没有自己的实现,TreeSet所有的方法都是调用TreeMap的方法
1. TreeSet类的add方法实现
1
2
3
4
5
6
7
8
9
10
11// map集合
private transient NavigableMap<E,Object> m;
// 通过构造方法创建TreeMap集合对象
public TreeSet() {
this(new TreeMap<E,Object>());
}
// TreeSet集合的add方法
public boolean add(E e) {
// 调用TreeMap集合的put方法
return m.put(e, PRESENT)==null;
}Set接口之LinkedHashSet类
1. LinkedHashSet类概述
LinkedHashSet类没有自己的方法所用的是继承HashSet的方法,所有使用的方法也都是基于HashSet类而HashSet类中创建对象有两个,一个是HashMap一个LinkedHashMap,而其中LinkedHashMap是供LinkedHashSet使用,LinkedHashSet集合是有序的(存储顺序与调用顺序一致)
2. LinkedHashSet类的构造方法
1
2
3
4
5
6
7
8
9
10// 使用空参构造方法创建LinkedHashSet对象
public LinkedHashSet() {
// 调用其父HashSet构造方法创建LinkedHashMap对象,使用LinkedHashMap方法
super(16, .75f, true);
}
// 使用指定初始化容量的构造方法创建LinkedHashSet对象
public LinkedHashSet(int initialCapacity) {
// 调用其父HashSet构造方法创建LinkedHashMap对象,使用LinkedHashMap方法
super(initialCapacity, .75f, true);
}3. LinkedHashSet类的构造方法
public boolean add(E e):向集合中添加元素方法boolean addAll(Collection<? extends E> c):向集合中添加指定集合的所有数据public boolean contains(Object o):判断集合中是否包含某一个指定的元素public boolean remove(Object o):从集合中移除指定元素,如果成功则返回true,否则返回falsepublic int size():返回集合中元素数量public boolean isEmpty():判断集合是否为空public Iterator<E> iterator():返回此集合的迭代器对象public void clear():移除集合中所有的元素
4. LinkedHashSet类的代码案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46public class LinkedHashSetDemo {
public static void main(String[] args) {
// 创建LinkedHashSet集合对象
Set<String> set = new LinkedHashSet<>();
// 1. `public boolean add(E e)`:向集合中添加元素方法
set.add("彭于晏");
set.add("吴彦祖");
set.add("梅超风");
set.add("灭绝师太");
set.add("川建国");
set.add("基尼太美");
set.add("古校长");
set.add("彭于晏");
System.out.println(set);
// 2. `boolean addAll(Collection<? extends E> c)`:向集合中添加指定集合的所有数据
List<String> list = new ArrayList<>();
list.add("彭于晏");
list.add("古校长");
list.add("古天乐");
list.add("渣渣辉");
list.add("小泽老师");
set.addAll(list);
System.out.println(set);
// 3. `public boolean contains(Object o)`:判断集合中是否包含某一个指定的元素
System.out.println(set.contains("灭绝师太"));
// 4. `public boolean remove(Object o)`:从集合中移除指定元素,如果成功则返回true,否则返回false
System.out.println(set.remove("基尼太美"));
System.out.println(set.remove("基尼太美"));
System.out.println(set);
// 5. `public int size()`:返回集合中元素数量
System.out.println(set.size());
// 6. `public boolean isEmpty()`:判断集合是否为空
System.out.println(set.isEmpty());
System.out.println("==================================");
// 7. `public Iterator<E> iterator()`:返回此集合的迭代器对象
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
// 8. `public void clear()`:移除集合中所有的元素
System.out.println("调用clear方法");
set.clear();
System.out.println(set);
System.out.println(set.isEmpty());
}
}集合中的Comparator比较器
1. Comparator比较器概述
Comparator比较器作用是用于集合的自定义排序,排序规则分为两种,1. 升序;2. 降序;
注意:集合的构造方法中带有Comparator比较器参数就代表,给其添加元素时元素必须要有实现Comparator比较器,或者使用外部比较器实现2. 使用Set集合的比较器案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68public class ComparatorDemo {
public static void main(String[] args) {
// 调用Set集合的比较实现
func01();
}
// Set集合的比较
public static void func01() {
// 使用TreeSet的比较器构造方法创建对象,其中Comparator比较器使用外部比较器
Set<String> set = new TreeSet<>(new Comparator<String>() {
/**
* 比较方法
* @param o1 字符串1
* @param o2 字符串2
* @return 返回字符串1与字符串2的对比
*/
@Override
public int compare(String o1, String o2) {
return o1.compareTo(o2);
}
});
// 1. `public boolean add(E e)`:向集合中添加元素方法
set.add("1");
set.add("2");
set.add("3");
set.add("4");
set.add("5");
// [死侍, 绿巨人, 美国翘臀, 蜘蛛侠, 黑寡妇]
// [黑寡妇, 蜘蛛侠, 美国翘臀, 绿巨人, 死侍]
System.out.println(set);
// 使用自定义对象创建外部比较器的TreeSet集合对象
Set<Person> persons1 = new TreeSet<>(new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
// 使用年龄排序
// return o2.getAge() - o1.getAge();
// 按照名称排序
// return o1.getName().compareTo(o2.getName());
String o1Name = o1.getName();
String o1Sex = o1.getSex();
Integer o1Age = o1.getAge();
String o2Name = o2.getName();
String o2Sex = o2.getSex();
Integer o2Age = o2.getAge();
// 将所有的值相加然后使用String类的compareTo方法
String personString1 = o1Name + o1Sex + o1Age;
String personString2 = o2Name + o2Sex + o2Age;
return personString1.compareTo(personString2);
}
});
persons1.add(new Person("孙悟空", "妖", 1000));
persons1.add(new Person("猪八戒", "妖", 900));
persons1.add(new Person("沙悟净", "妖", 800));
persons1.add(new Person("白龙马", "龙", 200));
persons1.add(new Person("唐玄奘", "人", 500));
persons1.add(new Person("白骨精", "妖", 300));
System.out.println(persons1);
// 使用Person自定义对象创建内部比较器,进行比较,所有的带有比较器的集合添加的数据都必须实现比较器接口
// 如果Person没有实现比较器并且没有使用外部比较器则无法直接添加到TreeSet集合中
Set<Person> persons2 = new TreeSet<>();
persons2.add(new Person("孙悟空", "妖", 1000));
persons2.add(new Person("猪八戒", "妖", 900));
persons2.add(new Person("沙悟净", "妖", 800));
persons2.add(new Person("白龙马", "龙", 200));
persons2.add(new Person("唐玄奘", "人", 500));
persons2.add(new Person("白骨精", "妖", 300));
System.out.println(persons2);
}
}3. 使用List集合的比较器案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27public class ComparatorDemo {
public static void main(String[] args) {
// 调用List集合的比较实现
func02();
}
// List集合的比较
public static void func02() {
// 实现List结合的比较方法sort
List<Person> persons = new ArrayList<>();
persons.add(new Person("孙悟空", "妖", 1000));
persons.add(new Person("猪八戒", "妖", 900));
persons.add(new Person("沙悟净", "妖", 800));
persons.add(new Person("白龙马", "龙", 200));
persons.add(new Person("唐玄奘", "人", 500));
persons.add(new Person("白骨精", "妖", 300));
System.out.println(persons);
// 调用sort排序方法
persons.sort(new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
return o1.getAge() - o2.getAge();
}
});
// 输出结果
System.out.println(persons);
}
}HashMap与HashSet集合中添加自定义对象重复原因
1. 数据重复的原因
已知HashMap的Key和HashSet集合中不能添加重复数据,而我们自定义对象却可以重复,其根本原因是Map中的put方法验证Key是否重复使用的是hashCode和equals方法验证,而自定义类在不重写的情况下使用的是父类Object类的方法,所以计算的结果都不同,也就导致了添加时会重复的原因,一旦重写hashCode和equals方法后则不会出现此问题
2. 解决数据重复
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74public class Person implements Comparable<Person> {
private String name;
private String sex;
private Integer age;
public Person() {
}
public Person(String name, String sex, Integer age) {
this.name = name;
this.sex = sex;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", sex='" + sex + '\'' +
", age=" + age +
'}';
}
/**
* 实现Comparable接口重写compareTo方法实现排序
*
* @param o 传入的Person对象
* @return 返回计算的结果(整数类型)
*/
@Override
public int compareTo(Person o) {
// 使用年龄排序
return this.age - o.age;
}
// 重写equals
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(name, person.name) && Objects.equals(sex, person.sex) && Objects.equals(age, person.age);
}
// 重写hashCode
@Override
public int hashCode() {
return Objects.hash(name, sex, age);
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26public class CustomizeObjectDemo {
public static void main(String[] args) {
// 使用自定义对象,向Set集合中添加数据
// 会出现数据重复的问题,其原因是因为map中的put方法比较时是使用hashCode和equals方法去判断的
Set<Person> persons = new HashSet<>();
// 设置数据
persons.add(new Person("孙悟空", "妖", 1000));
persons.add(new Person("猪八戒", "妖", 900));
persons.add(new Person("沙悟净", "妖", 800));
persons.add(new Person("白龙马", "龙", 200));
persons.add(new Person("唐玄奘", "人", 500));
persons.add(new Person("白骨精", "妖", 300));
// 添加重复数据
persons.add(new Person("孙悟空", "妖", 1000));
persons.add(new Person("猪八戒", "妖", 900));
persons.add(new Person("沙悟净", "妖", 800));
persons.add(new Person("白龙马", "龙", 200));
persons.add(new Person("唐玄奘", "人", 500));
persons.add(new Person("白骨精", "妖", 300));
// 使用迭代器打印数据
Iterator<Person> iterator = persons.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}集合工具类Collections
1. Collections是Java提供的操作集合的工具类,也是一个鸡肋产品,提供了部分的集合方法,例如排序等等
2. Collections中的方法
public static <T extends Comparable<? super T>> void sort(List<T> list):排序方法,默认升序并且无法更改降序public static <T> void sort(List<T> list, Comparator<? super T> c):升序加降序都可以的public static void shuffle(List<?> list):混乱排序public static void reverse(List<?> list):将集合倒转
3. Collections代码案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32public class CollectionsDemo {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("超人");
list.add("蝙蝠侠");
list.add("钢骨");
list.add("神奇女侠");
list.add("海王");
list.add("海王");
list.add("火星猎人");
System.out.println(list);
// 1. `public static <T extends Comparable<? super T>> void sort(List<T> list)`:排序方法,默认升序并且无法更改降序
Collections.sort(list);
System.out.println(list);
// 2. `public static <T> void sort(List<T> list, Comparator<? super T> c)`:升序加降序都可以的
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o2.compareTo(o1);
}
});
System.out.println(list);
// 3. `public static void shuffle(List<?> list)`:混乱排序
Collections.shuffle(list);
System.out.println(list);
// 4. `public static void reverse(List<?> list)`:将集合倒转
Collections.sort(list);
System.out.println(list);
Collections.reverse(list);
System.out.println(list);
}
}
Java集合体系https://github.com/i-xiaoxin/2022/09/21/java集合体系/